Semantic Search with Vertex AI
Firebase
Sep 12, 2023
Introduction
Searching allows developers to effectivly identity records in a database based on a query. With Firebase the Firebase SDKs, developers can execute compound queries on a collection to search for specific records.
An alternative approach would be to query directly through an API endpoint.
Introducing the Semantic Search with Vertex AI extension. With this extension installed, you can use the power of AI to index and return Firestore documents automatically through on a text based query.
Semantic Search with Vertex AI extension
This extension adds text similarity search to your Firestore application using Vertex AI’s Matching Engine. It allows you to bring search capabilities to your Firestore database.
By automatically creating embeddings of your data and syncing with Vertex Vector search, this extension allows developers to search for any documents based on a search term.
An authenticated HTTP endpoint is provided to developers to integrate with their applications seamlessly.
Getting Started with the Extension
Before you begin, you’ll need a Firebase project with Cloud Firestore and Cloud Storage configured. Follow these steps to set up:
Once your project is ready, add the Semantic Search with Vertex AI extension.
Extension Installation
You can install the “Semantic Search with Vertex AI” extension via the Firebase Console or Firebase CLI.
Option 1: Firebase Console
Visit the Firebase Extension’s page and locate the “Semantic search with Vertex AI“ extension. Click “Install in Firebase Console” and set up the configuration parameters.

Option 2: Firebase CLI
Alternatively, install the extension using the Firebase CLI with the command:
firebase ext:install googlecloud/firestore-semantic-search --project=projectId_or_alias
Configure Parameters
To optimize the “Semantic Search with Vertex AI” Firebase extension for your specific needs, it’s essential to understand and set its configuration parameters appropriately.
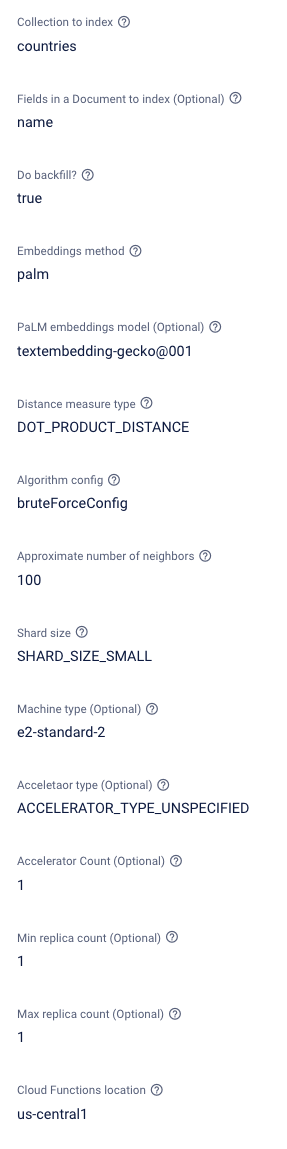
Here’s a breakdown of each parameter:
- Collection to Index: This is the Firestore collection containing the documents to index in the Vertex Matching engine. An example would be products, to provide a product search for your application.
- Fields in a document to index (Optional): Specified fields ensure that the matching engine only indexes the relevant fields and data in the matching engine. In our product example, we would choose fields such as name and description to get the best results from the search queries.
- Do Backfill?: As mentioned in the introduction, if enabled, this extension will index all of your existing documents in your specified collection as part of the installation process. This ensures that all existing documents are included in your search results.
- Embedding method: When indexing data for the Vertex engine, data must be converted to embeddings - you will typically need to select an embedding format to do this! The extension has two options:
- PaLM embeddings are provided by Google through the PaLM API.
- Universal Sentence Encoder (USE) is an open-source approach provided by TensorFlow.
- PaLM is recommended; however, Consider USE as a good alternative if you do not have access to the PaLM API.
- PaLM embeddings model: If you choose PaLM for the embeddings format, then you must select a model type to go with it. One option is currently available:
- Embedding-gecko
- If you selected USE, then this option can be ignored.
- Distance measure type: A matching engine uses the nearest neighbor to find close matches. There are several algorithms available for choosing how your extension approaches this. You can choose from the following options:
- Squared Euclidean distance
- Manhattan distance
- Cosine distance
- Dot product
- You can read more about distance measure types here.
- Algorithm config: Several algorithms are available for choosing how your extension searches through indexed data. You can choose from the following options:
- Tree AH Config
- Brute force config
- You can read more about algorithm configuration here.
- Approximate number of neighbors: The search algorithm will return the number of neighbors (similar results).
- Shard Size: Vertex will store the provided vector data and automatically index through sharding. A description of the available shard sizes can be found here.
- Machine Type: On installation, the extension will also create a server based on what size machine type has been configured. A description of the available machine types can be found here.
- Accelerator type: This is optional and can be left unspecified. If you would like the performance of the matching engine, then you can add an accelerator. The complete list is listed here.
- Accelerator count: If an accelerator type has been added, this option sets how many accelerators of the selected type to add to your matching engine.
- Min replica count: An index endpoint is deployed as part of this extension and can be replicated to handle large traffic volumes. This option states the minimum number of instances available by default.
- Max replica count: Similar to the minimum replica count. Additional replicas will be created when much traffic has been detected. This option states the maximum number of replicas the endpoint will scale.
- Cloud functions Location: Where do you want to deploy the functions created for this extension? For help selecting a location, refer to the location selection guide.
How it works
Once the “Semantic Search with Vertex AI Extension” has been installed, a few checks must be completed. Real-time updates for these updates are stored in the Firestore database under a new collection called _ext-firestore-semantic-search.
Backfill documents: If selected, all documents within the specified collection will be automatically indexed in the Vertex database.
Send request: A callable function request is made through the client, this will contain the search text to query with.
Vertex search: The extension will then forward the query to the Vertex Matching Engine, which will return a list of document Ids in a json array format.
Database query: Once a successful response has been received, a Firestore Query can then be made by the client to return the documents based on the document Ids.

Backfilling
You can monitor this progress by navigating to the ext-firestore-semantic-search collection; here, you will find the backfilled documents and appropriate metadata under the tasks document.

Resource Deployment
Once the extension has been installed, a series of tasks are started that manage the process of building your Vertex engine and index endpoint.
Navigate to the metadata document of the extensions collection. Here, you will find updates for deploying your index and endpoint.

Continue to monitor this; once ready, you can start using your new extension.
If you would like to use the GCP UI for tracking this part of the installation, navigate to https://console.cloud.google.com/vertex-ai/matching-engine/indexes
Running your first search
You will now have access to an authenticated HTTP endpoint. There are two ways provided by Firebase to query the matching engine.
- Executing a command through the CLI
- Executing a callable function through a client application.
In either method, you will receive a JSON response. Inside this response, you will notice a combination of metadata and document IDs, which represent the Firestore documents. Let’s take a look at an example:
{
"nearestNeighbors": [
{
"id": "0",
"neighbors": [
{
"datapoint": {
"datapointId": "zVnAFpQQd6LDntOPhWlk",
"crowdingTag": {
"crowdingAttribute": "0"
}
},
"distance": 0.40997931361198425
},
{
"datapoint": {
"datapointId": "VjdCBMgq939nUB846TZ2",
"crowdingTag": {
"crowdingAttribute": "0"
}
},
"distance": 0.36510562896728516
},
...
]
}
]
}
In this example response, you will notice a neighbors array. This is the list of search results and contains the following data:
- Datapoint: This is your document result. The included documentId represents the Firestore document, which you can then run a query on to get the complete data.
- distance: This number denotes how close in accuracy the resulting document is to your provided search query.
Through the Command line interface(CLI)
To demonstrate the search capabilities outside of an application. Try running the following command:
gcloud functions –project rc-release-testing call ext-firestore-semantic-search-queryIndex –data ‘{“data”: {“query”:[“”]}}’
The search requires a single text search input, eg, “I am a query”. Add this to your query example above to see the results.
Note, if you need to learn how to install gcloud command, you can learn more here.
Using a client application
The installed extension creates an onCall function. These special HTTP functions will automatically ensure that the request has come from a user who is currently logged into the application.
This ensures that the endpoint cannot be accessed as a public endpoint and used by anyone!
First, initialize your Firebase app.
import { initializeApp } from 'firebase/app';
import { getFirestore } from 'firebase/firestore';
import { getAuth } from 'firebase/auth';
import { getFunctions } from 'firebase/functions';
const firebaseConfig = {
// Your Firebase configuration keys
};
const app = initializeApp(firebaseConfig);
const firestoreRef = getFirestore(app);
const functionsRef = getFunctions(app);
const authRef = getAuth(app);
To use this in a Firebase application, you must use the httpscallable function from the Firebase functions library. First, set up the Firebase SDK in your application:
import firebase from "firebase";
import { getFunctions, httpsCallable } from "firebase/functions";
const functions = getFunctions();
const search = httpsCallable(functions, `ext-${param:EXT_INSTANCE_ID}-queryIndex`);
await search({ query: searchQuery })
.then(async (result) => {
// get results
const { nearestNeighbours } = result.data;
const paths = nearestNeighbours.neighbours.map($ => $.datapoint.datapointId);
// fetch documents from Firestore using the ids...
});
As an onCall function is required, we should log in before running a search.
We can do this by signing in as an anonymous user:
signInAnonymously(authRef).then(() => {
console.log('Signed in anonymously');
});
Once signed in, we can define a callable function. We will use this to send our search query.
const search = httpsCallable(
functionsRef,
`ext-firestore-semantic-search-queryIndex`
);
Finally, we can add a listener to our search button and then use the field value to execute the search:
/** Consider having a Button in your UI **/
const searchBtnText = document.getElementById('search-btn');
const collectionName = 'countries';
searchBtnText.addEventListener('click', async () => {
await search({ query: [inputText.value] }).then(async (result) => {
const { nearestNeighbors } = result.data.data;
for (const neighbor of nearestNeighbors[0].neighbors) {
/** Get the document based on the collection name and document Id */
const documentRef = doc(
firestoreRef,
collectionName,
neighbor.datapoint.datapointId
);
/** Load the document snapshot */
const documentSnap = await getDoc(documentRef);
/** Extract the field data */
const { name } = documentSnap.data();
/** Update UI */
console.log(name);
}
});
});
Running this will now provide you with document data ordered by search.

Conclusion
Installing the Semantic Search with Vertex AI extensions provides practical search functionality you can add to any application, providing useful metadata for customization or a better understanding of results.