Language Tasks with PaLM API
Firebase
Sep 12, 2023
Introduction
Language processing tasks enable applications to understand and generate natural language seamlessly. With thePaLM API Firebase extension, developers can effortlessly integrate robust language models into their client applications without requiring intricate server setups.
Language Tasks with PaLM API
The Language tasks with PaLM API Firebase extension leverages the PaLM API to bring advanced language processing capabilities to Firebase applications. By seamlessly integrating with PaLM, the extension enables developers to perform AI language tasks on text, with the added flexibility of customization through prompt engineering.
PaLM API, renowned for its powerful language models, allows developers to effortlessly incorporate natural language understanding and text generation into their applications. This collaborative effort between Google Cloud and Firebase simplifies the integration process, providing a user-friendly solution for executing sophisticated language tasks.
Getting Started with the Extension
Extension Installation
You can install the “Language Tasks with PaLM API“ extension via the Firebase Console or Firebase CLI.
Option 1: Firebase Console
Visit the Firebase Extension’s page and locate the “Language Tasks with PaLM API” extension. Click “Install in Firebase Console” and set up the configuration parameters.

Option 2: Firebase CLI
Alternatively, install the extension using the Firebase CLI with the following command:
firebase ext:install googlecloud/firestore-palm-gen-text --project=YOUR_PROJECT_ID
Note: you need to be at the root of a Firebase project.
Configure Parameters
Configuring the “Language Tasks with PaLM API” extension involves several parameters to help you customize it. Here’s a breakdown of each parameter:
Palm API Provider:
- Description: There are two APIs for accessing PaLM’s language models: the PaLM Developer (Generative Language) API and Vertex AI. We recommend Vertex AI for production scenarios because the Generative Language API is still in its public preview phase.
- For more details on the Vertex AI PaLM API, see the Vertex AI documentation.
API Key (Generative Language AI for Developers Provider ONLY) (Optional):
- Description: If you choose Generative AI for Developers as your PaLM API provider, you can provide an API key optionally. Without an API key, the extension uses Default Credentials, requiring the service to be enabled in GCP.
- The PaLM developer (Generative Language) API is currently in public preview, and you will need to sign up for thewaitlist if you want to use it. For details and limitations, see the PaLM API documentation.
Collection Path:
- Description: Specify the Firestore collection that holds the documents with the text you want to process with the Language Tasks with PaLM API. This path guides the extension to the particular collection to observe.
- Example:
generate
Prompt:
- Description: A prompt is an instruction to the LLM. In this use case, the prompt asks to evaluate and assign a star rating between 1 and 5 to a given review text. It is structured as: “Provide a star rating for the following review text.” This format is designed to align seamlessly with the response field, even when variable fields are included.
- Example:
Provide a star rating from 1-5 of the following comment text and 5 is the best comment, and 1 is very bad: "{{comment}}"
Variable fields (Optional):
- Description: A list of fields, separated by commas, to be substituted as variables in the prompt.
- Example:
comment
Response Field:
- Description: Select the field in the Firestore document where you want the PaLM API response written.
- Example:
output
Cloud Functions Location:
- Description: For optimized performance, choose the deployment location for the extension’s functions, ideally close to your database.
- Location Selection Guide
Language model:
- Description: Select the desired language model for processing tasks.
- Example:
text-bison-001 - More info about language model
Temperature:
- Description: Control the randomness of the output, ranging from 0 to 1. Higher values produce more varied responses.
Nucleus Sampling Probability:
- Description: This value represents top_p and configures the nucleus sampling. It sets the maximum cumulative probability of tokens to sample from. Specify a lower value for less random responses and a higher value for more random responses. Enter a value between 0 and 1.
Sampling Strategy Parameter:
- Description: Top-K changes how the model selects tokens for output. A top-K of 1 means the next selected token is the most probable among all tokens in the model’s vocabulary (also called greedy decoding), while a top-K of 3 means that the next token is selected from among the three most probable tokens by using temperature.
- For each token selection step, the top-K tokens with the highest probabilities are sampled. Then tokens are further filtered based on top-P with the final token selected using temperature sampling.
- Specify a lower value for less random responses and a higher value for more random responses. The default top-K is 40.
Candidate Count:
- Description: Store additional candidate responses in Firestore under the ‘candidates’ field when set to an integer higher than one. Applicable only if you selected the Generative Language API for Developers.
Candidates Field:
- Description: Identify the field in the message document to store other candidates’ responses. Applicable only if you selected the Generative Language API for Developers.
Maximum Number of Tokens:
- Description: Maximum number of tokens that can be generated in the response. A token is approximately four characters. 100 tokens correspond to roughly 60-80 words. It should be an integer in the range [1,1024] for text-bison@001, [1, 2048] for the latest.
Content Thresholds (Generative Language PaLM API Only) Derogatory, Toxic, Sexual, Violent, Medical, Dangerous, Unspecified Harm:
- Description: You must define certain thresholds for blocking content within their categories. This critical step will allow you to control the content being generated better. Please note that this step only applies when using the Generative Language PaLM API. By setting these thresholds, you can ensure that the content generated falls within acceptable parameters, thus improving the quality and relevance of the output.
How it works
Once the “Language Tasks with PaLM API” extension is installed and set up, it enables an automated process for executing advanced language tasks on your text.
- Document Write Trigger: Whenever a new document is written to the specified Firestore collection, it triggers the extension.
- Prompt Substitution: The extension replaces any variables in the prompt with corresponding values from the triggering document. This allows the prompt to be personalized for each document.
- PaLM API Query: The extension sends the personalized prompt to the PaLM API, which uses its powerful language processing capabilities to generate a response.
- Response Writing: The extension receives the response from the PaLM API and writes it back to the triggering document in the specified response field. This makes the response easily accessible for further processing or use.
Each instance of the extension is configured to perform a specific task. This ensures the extension is optimized for the particular task and provides consistent and accurate results.

Steps to Integrate Language Tasks with PaLM API
To integrate the “Language Tasks with PaLM API” Firebase extension into your application, initialize the Firebase SDK and ensure access to Firebase Cloud Storage and that Firestore is configured.
Step 1: Initial Setup
First, set up the Firebase SDK in your application:
import { initializeApp } from 'firebase/app';
import { getStorage, ref, uploadBytes, getDownloadURL } from 'firebase/storage';
import { getFirestore, doc, onSnapshot } from 'firebase/firestore';
const firebaseConfig = {
// Your Firebase configuration keys
};
const app = initializeApp(firebaseConfig);
const storage = getStorage(app);
const firestore = getFirestore(app);
UI for submitting the review comment
Include a UI component in your application for text input and submission.
<!-- HTML input elements for comment submission -->
<input id="input-text" />
Add the logic to handle text submission.
const inputText = document.getElementById('input-text');
const submitText = document.getElementById('submit-text');
inputText.addEventListener('input', (e) => {
const value = e.target?.value.trim();
if (value) {
submitText.removeAttribute('disabled');
}
});
document
.getElementById('submit-text')
.addEventListener('click', handleSubmitText);
let text;
function handleSubmitText() {
if (inputText?.value?.trim()) {
submitText.setAttribute('disabled', 'true');
textForLanguageTasks = inputText.value.trim();
submitTextToFirestore(textForLanguageTasks);
}
}
Write the text to the specified Firestore collection that the extension monitors.
function submitTextToFirestore(text) {
const textCollectionRef = collection(firestoreRef, 'generate');
let docId;
addDoc(textCollectionRef, { comment: text })
.then((docRef) => {
docId = docRef.id;
/** Set a 5 second timeout */
setTimeout(() => {
getCommentAndOutput(docRef.id);
}, 5000);
console.log('Text submitted for conversion:', docRef.id);
})
.catch((error) => {
submitText.removeAttribute('disabled');
console.log('Error submitting text:', error);
});
}
This function adds the user’s text to a Firestore collection named generate. It then sets a timeout to wait 5 seconds before calling getCommentAndOutput to retrieve and display the converted output.
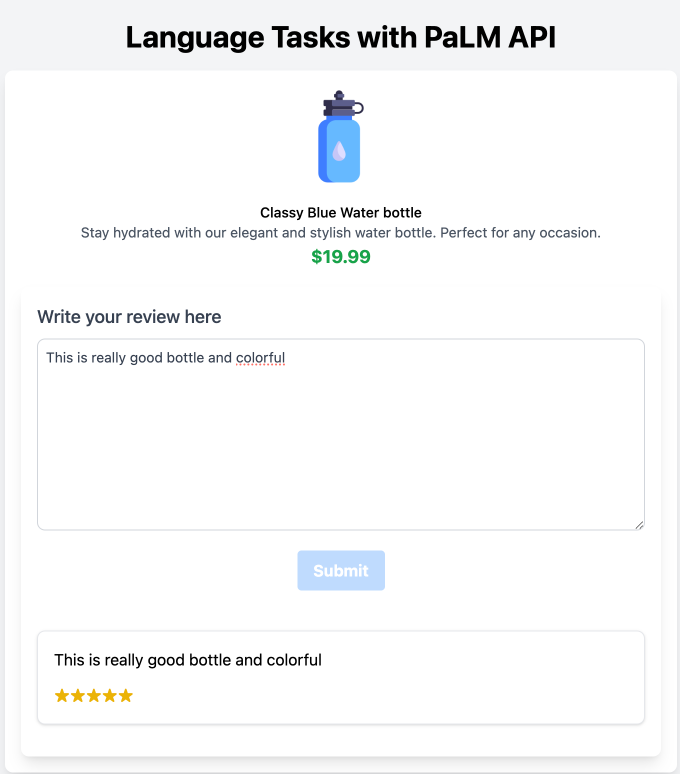
Step 2: Monitor Language Tasks and Retrieve Results
The extension processes the submitted text for language tasks, and once it’s done, you can retrieve the results from the same document in Firestore.
function getCommentAndOutput(docId: string) {
const docRef = doc(firestoreRef, 'generate', docId);
getDoc(docRef)
.then((doc) => {
if (doc.exists()) {
const comment = doc.data().comment;
const output = doc.data().output;
// Update UI accordingly
})
.catch((error) => {
console.log('Error getting document:', error);
});
}
This function retrieves the converted comment and rating from Firestore using the document ID. It then creates a new review entry and adds it to the reviews array. This array can display several stars corresponding to the rating the PaLM API provides.