Multimodal Tasks with Gemini
Firebase
Dec 18, 2023
Introduction
Powered by Gemini, Google’s state-of-art Large Language Model (LLM), this extension helps to easily perform generative tasks using Gemini’s large language models, allowing users to store and manage conversations in Cloud Firestore.
The Multimodal Tasks with Gemini extension provides an out-of-the-box solution allowing you to perform AI/ML tasks on text and images, customizable with prompt engineering.
Google AI
Google DeepMind has released its newest Large Language Model (LLM) called Gemini. This solution includes a new range of features for allowing developers to converse and interact with AI easily.
Gemini offers a range of features and capabilities including:
A Multimodal approach
Gemini provides a multimodal approach, allowing it to understand and process various forms of information. This also allows users to combine different types of content such as text, code, audio, images, and video to generate AI responses.
Deliberate Reasoning
Gemini surpasses previous models in its ability to engage in deliberate reasoning. This means that the language model is not only capable of processing and understanding information but also of applying logical reasoning to solve problems and make decisions.
Human-quality Text Generation
Gemini generates human-quality text, which means that it can create realistic and engaging narratives, write different kinds of creative content, and even translate languages.
Model Sizes
This extension uses the Gemini Pro and Gemini Pro Vision chat models for handling requests.
Google AI API
This Firebase extension uses the Google AI API (for developers) and Vertex AI to communicate with Gemini.
Getting Started
Before installing, ensure you have a Firebase project set up. If it’s your first time, here’s how to get started:
This extension allows images to be sent in either a base64 or Google Cloud Storage (GCS) url formats. Ensure you have set up Cloud Storage if you would like to use GCS urls.
Once your project is prepared, you can integrate the Multimodal Tasks with Gemini extension into your application.
Extension Installation
Installing the “Multimodal Tasks with Gemini” extension can be done via the Firebase Console or using the Firebase CLI.
Option 1: Firebase Console
Find your way to the Firebase Extensions catalog, and locate the “Multimodal Tasks with Gemini“ extension. Click Install in Firebase Console and complete the installation process by configuring your extension’s parameters.

Option 2: Firebase CLI
For those who prefer using command-line tools, the Firebase CLI offers a straightforward installation command:
firebase ext:install googlecloud/firestore-multimodal-genai --project=projectId-or-alias
Configure Parameters
Configuring the “Multimodal Tasks with Gemini” extension involves several parameters to help you customize it. Here’s a breakdown of each parameter:
To quickly get started with this extension, there are up to four fields which must be provided.
Required Configuration
Cloud Functions location
The location field should represent the closest location to where your project is located. In this example we are going to select Iowa (us-central1). See this guide for more information on cloud function locations.
Prompt
A prompt will represent the query that will be sent to the Gemini AI with every input from the user. To ensure customisation per request, this field can substitute values through handlebars. Here, we should include a message that has a value that can be substituted for each document that is written:
- Provide a star rating from 1-5 of the following review text: {{comment}}
Based on handlebars configuration, the{{comment}}field will be replaced with the appropriate text before sending the prompt to Gemini.
Default Parameters
Gemini API Provider
Since Google AI requires an API key, you have the option to choose Vertex AI instead, which authenticates requests using application default credentials.
Generative Model
This extension offers two approaches for sending information to Gemini:
- Gemini Pro: For sending text based requests.
- Gemini Pro Vision: For sending text and image based requests
This guide demonstrates how both of these models can be used to produce a response from Gemini.
Each of these models require a bit of customization, the How it works guide below will demonstrate how to configure the extension for each scenario.
Optional Parameters
API key (A required field for Google AI)
If you selected Google AI as the Gemini API provider, you will need to provide a Google AI API key. This can be obtained through Google AI Studio.
To generate a key:
- Select Get API key.
- Select Create API key in new project or Create API key in existing project.
- Select the newly generated key and choose Copy.
Navigate back to your extension configuration and enter the value before selecting Create Secret.
This will store your secret securely in the Google Secret Manager.
Variable Fields (optional)
Based on the above prompt setting, we should now set the variable field to be comment, this should match the {{comment}} substitution value that was added to the prompt field.
Here’s a full demonstration of how the final result would look like:
prompt: Provide a star rating from 1-5 of the following review text: {{comment}}
comment: This a nice place, would give it another visit
The final result to be sent to Gemini by the extension, for example:
Provide a star rating from 1-5 of the following review text: This a nice place, would give it another visit
Image Field (A required field for Gemini Pro Vision only)
This field is for when using both a text and image prompt when sending a request to Gemini, and will only be used when the Gemini Pro Vision option has been selected.
This field will represent the Firestore field that contains an image value in one of two formats:
- Google Cloud Storage Url:: This must be in the format of
gs://{projectId}.appspot.com/{filePath} - Base64:: This a representation of an image that has been encoded as a Base64 string.
Gemini API Provider
This option provides a list of APIs that the extension will use to send and receive responses from Gemini. This currently has only one option, which is Google AI.
Language model
Gemini Pro provides conversation with the Gemini AI.
Gemini Pro Vision provides a mulit-modal approach, meaning that you can send both text and image data. This will return a text-based response.
Prompt Field
This is the Firestore field which contains the query from the user when adding a document in Firestore. Use handlebars to provide variable substitutions for on demand prompts when adding a new Firestore document.
Response Field
This is the Firestore field which contains the response from Gemini when adding a document in Firestore. This can remain as the recommended output value.
Candidate Count (optional)
The Gemini AI has the ability to return multiple responses, allowing users to select which is the most appropriate. In this instance we would like one response. Keep this value as 1
How it works
There are multiple approaches to using this extension, and this can depend on which model and approach you have chosen when configuring the extension. There are currently two options:
- Gemini Pro
- Gemini Pro Vision
The following section will demonstrate how you can use each option.
Process Text with Gemini Pro
In this section, we are using the following parameters to configure the extension:
- Language model: Gemini Pro
- Prompt: Provide a star rating from 1-5 of the following review text: {{comment}}
- Variable fields (optional): comment
To process text only with Gemini, we chose Gemini Pro as the language model.
Then, we provide context through a custom prompt to instruct the model on how to respond. In this case, the prompt asks Gemini to rate a review text on a scale of 5.
Finally, we have included a variable field to substitute custom values for each document, this will use a handlebars approach to inject the text value into the prompt on each request.
After installation and configuration, the extension will listen for any new documents that are added to the configured collection. To see it in action:
- Add a new document: By including a comment field with text, the AI will be prompted for a response.
- Tracking status: While a response from the AI is generated, the extension will update the current Firestore document with a status field. This field will include PROCESSING, COMPLETED and ERRORED responses.
- Successful responses: When the AI has returned a successful response. A new field will be added containing a response.
- Regenerating a response:: Updating the status field to anything over than “COMPLETED” will regenerate a response.
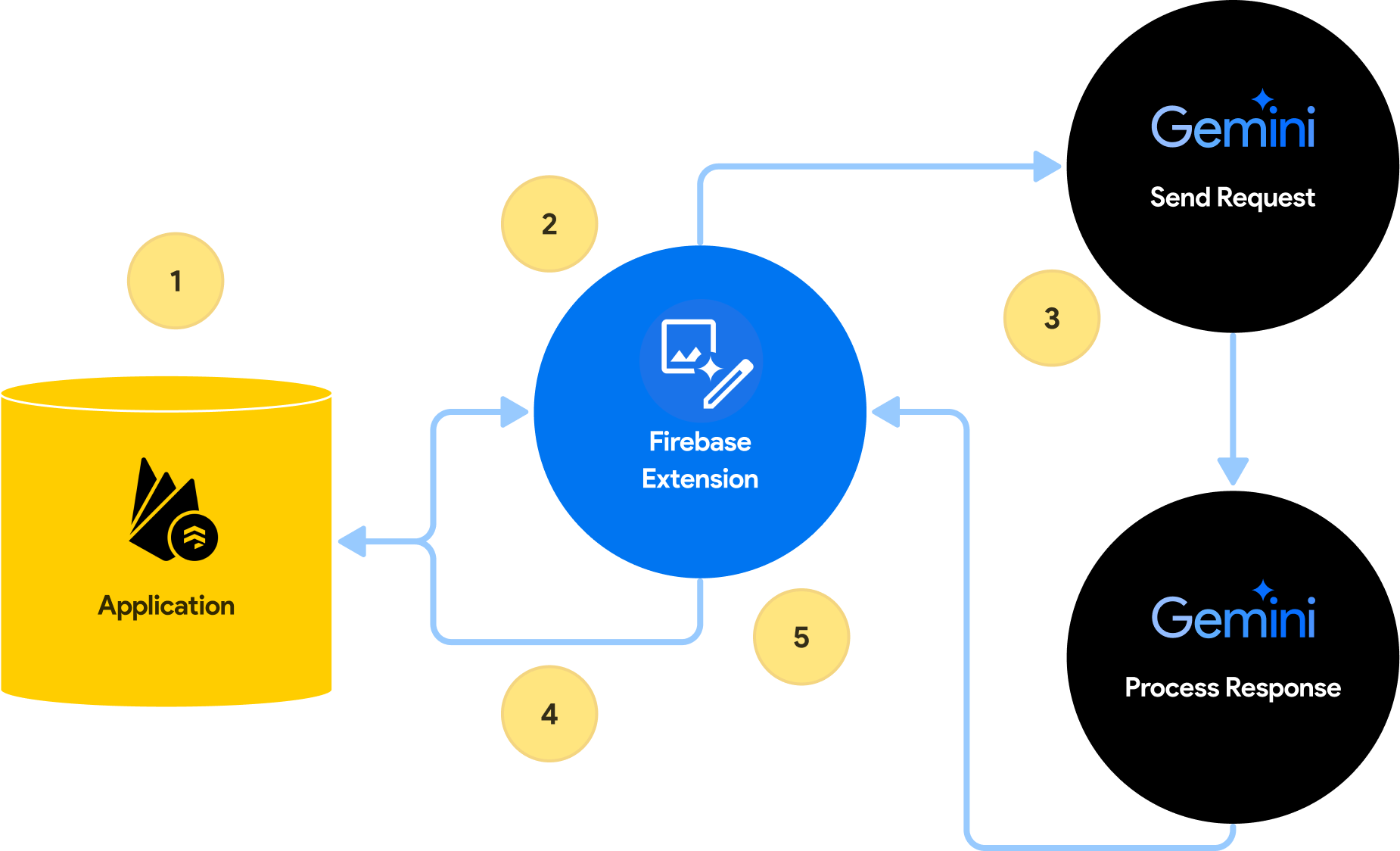
Steps to connect to the Multimodal Tasks with Gemini (Pro)
Before you begin, ensure that the Firebase SDK is initialized and you can access Firestore.
const firebaseConfig = {
// Your Firebase configuration keys
};
firebase.initializeApp(firebaseConfig);
const db = firebase.firestore();
Next, we can simply add a new document to the configured collection to start the conversation.
/** Add a new Firestore document */
await addDoc(collection(db, 'collection-name'), {
comment: 'The best food I have ever tasted!',
});
Listen for any changes to the collection to display the conversation.
/** Create a Firebase query */
const collectionRef = collection(db, 'collection-name');
const q = query(collectionRef, orderBy('createTime'));
/** Listen for any changes **/
onSnapshot(q, (snapshot) => {
snapshot.docs.forEach((change) => {
/** Get prompt and response */
const { prompt, response, status } = change.data();
/** Update the UI status */
console.log(status);
/** Update the UI prompt */
console.log(prompt);
/** Update the UI AI status */
console.log(response);
});
});
Process Text and Images with Gemini Pro Vision
In this section, we are using the following parameters to configure the extension:
- Language model: Gemini Pro Vision
- Prompt: {{instruction}}
- Variable fields (optional): instruction
- Image field (optional): image
To process prompts containing both text and images with Gemini, we chose Gemini Pro Vision as the language model
A prompt is included to direct Gemini, in this case we would like to provide a custom field along with the image. {{instruction}} represents the Firestore field that will be added to the document with the prompt we would like to be processed with the image.
In addition, we have included the Variable fields value, this will contain the instruction to send as a prompt alongside the chosen image.
Lastly, we have provided an image field which will store the image reference to use with the prompt from the user. Although optional on configuration, it is important to note that this value is mandatory, if you are to use a multi-modal approach.
After installation and configuration, the extension will listen for any new documents that are added to the configured collection. To see it in action:
- Add a new document: Two fields are required for the new document. A prompt field representing the text to send to Gemini, alongside you will need an image field based on the field name from your configuration. The image field value will be either a GCP Storage URL or a base64 encoded value of an image.
- Tracking status: While a response from the AI is generated, the extension will update the current Firestore document with a status field. This field will include PROCESSING, COMPLETED and ERRORED responses.
- Storage: If the image source is Google Cloud Storage(GCS), a buffer value of the image will be downloaded based on the url.
- Successful responses: When the AI has returned a successful response. A new field will be added containing a response alongside additional metadata.
- **Regenerating a response:**Updating the status field to anything other than “COMPLETED” will regenerate a response.
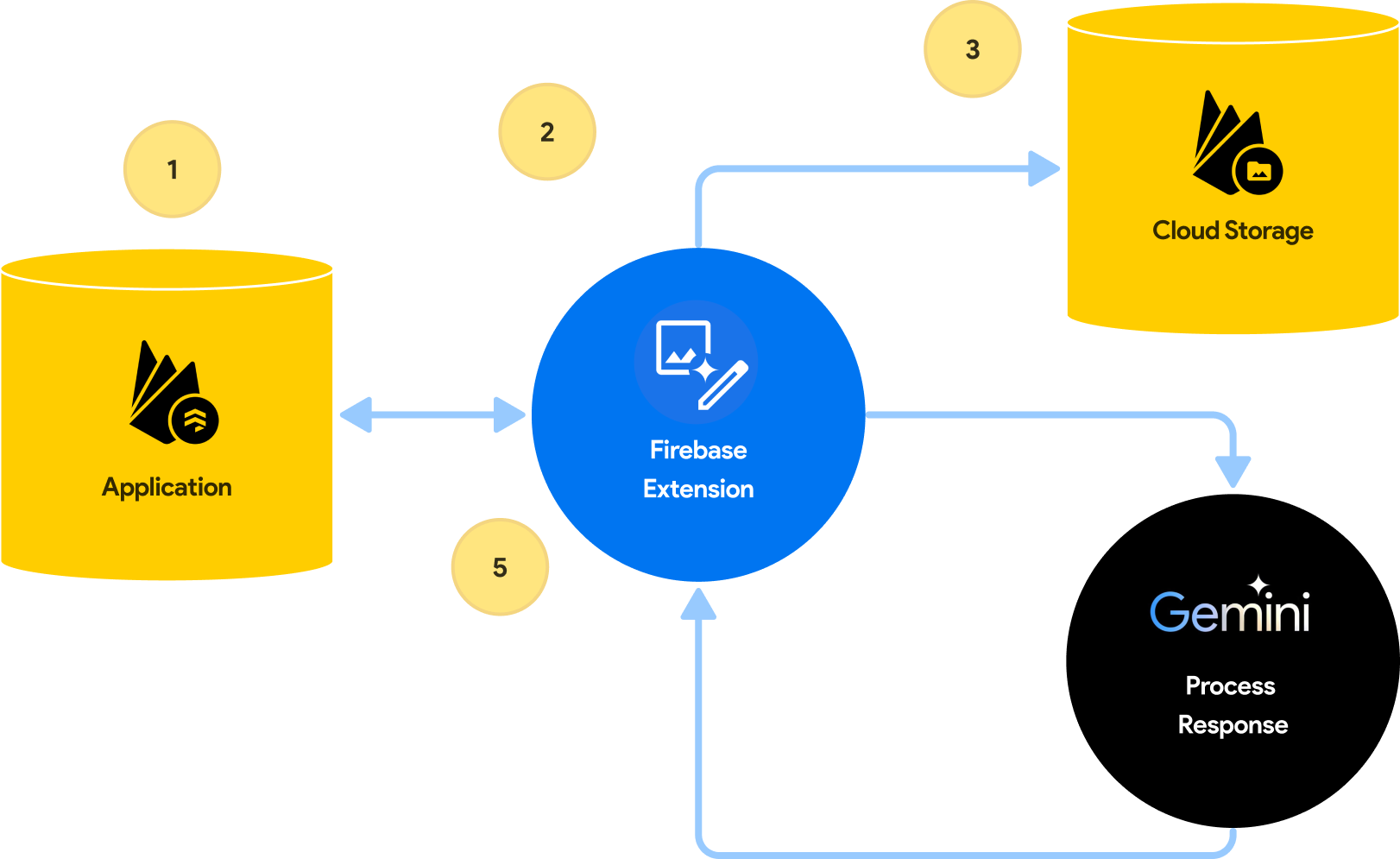
Steps to connect to the Multimodal Tasks with Gemini (Vision Pro)
Before you begin, ensure that the Firebase SDK is initialized and you can access Firestore.
const firebaseConfig = {
// Your Firebase configuration keys
};
firebase.initializeApp(firebaseConfig);
const db = firebase.firestore();
Next, we can simply add a new document to the configured collection to start the conversation.
/** Add a new Firestore document */
await addDoc(collection(db, 'collection-name'), {
instrction: 'What kind of flower is this?',
image: 'gs://example-image.jpg',
});
Listen for any changes to the collection to display the conversation.
/** Create a Firebase query */
const collectionRef = collection(db, 'collection-name');
const q = query(collectionRef, orderBy('createTime'));
/** Listen for any changes **/
onSnapshot(q, (snapshot) => {
snapshot.docs.forEach((change) => {
/** Get prompt and response */
const { instruction, output, status } = change.data();
/** Update the UI instruction */
console.log(instruction);
/** Update the UI output */
console.log(output);
/** Update the UI AI status */
console.log(status);
});
});
Conclusion
By installing the Multimodal Tasks with Gemini extension, you can receive highly efficient responses by simply adding a Firestore document with text and an image. Responses are highly configurable, allowing many customization options for developers.