Stream Firestore to BigQuery
Firebase
Dec 9, 2023
Introduction
Firestore offers an easy to integrate NoSQL storage solution, while providing real-time updates for your applications. BigQuery is an ideal choice for storing, analyzing, and deriving insights from larger datasets.
The Stream Firestore to BigQuery extension provides an out-of-the-box solution for syncing data in real-time between your Firestore and BigQuery database. This allows developers to provide an ideal back-end solution for your database, while also allowing database engineers to work with the big data!
BigQuery
Google BigQuery is a fully managed, serverless data warehouse designed to handle petabytes of data. It provides a cost-effective and scalable solution for storing, analyzing, and querying large datasets.
Features for this product include:
- Data analytics: BigQuery can be used to analyze large datasets to identify trends, patterns, and insights. This information can be used to improve business decisions, optimize marketing campaigns, and make better informed investments.
- Machine learning: BigQuery can be used to train and deploy machine learning models. This can be used to automate tasks, predict customer behavior, and improve product recommendations.
- Business intelligence: BigQuery can be used to create dashboards and reports that provide a visual representation of data. This can help businesses to understand their data better and make more informed decisions.
Getting Started with the Stream Firestore to BigQuery extension
Before you can access the Stream Firestore to BigQuery extension, ensure you have a Firebase project set up. If it’s your first time, here’s how to get started:
Once your project is prepared, you can integrate the Stream Firestore to BigQuery extension into your application.
Extension Installation
Installing the “Stream Firestore to BigQuery” extension can be done via the Firebase Console or using the Firebase CLI.
Option 1: Firebase Console
Find your way to the Firebase Extensions catalog, and locate the “Stream Firestore to BigQuery” extension. Click “Install in Firebase Console” and complete the installation process by configuring your extension’s parameters.

Option 2: Firebase CLI
For those who prefer using command-line tools, the Firebase CLI offers a straightforward installation command:
Configure Parameters
Configuring the “Stream Firestore to BigQuery” extension involves several parameters to help you customize it. Here’s a breakdown of each parameter:
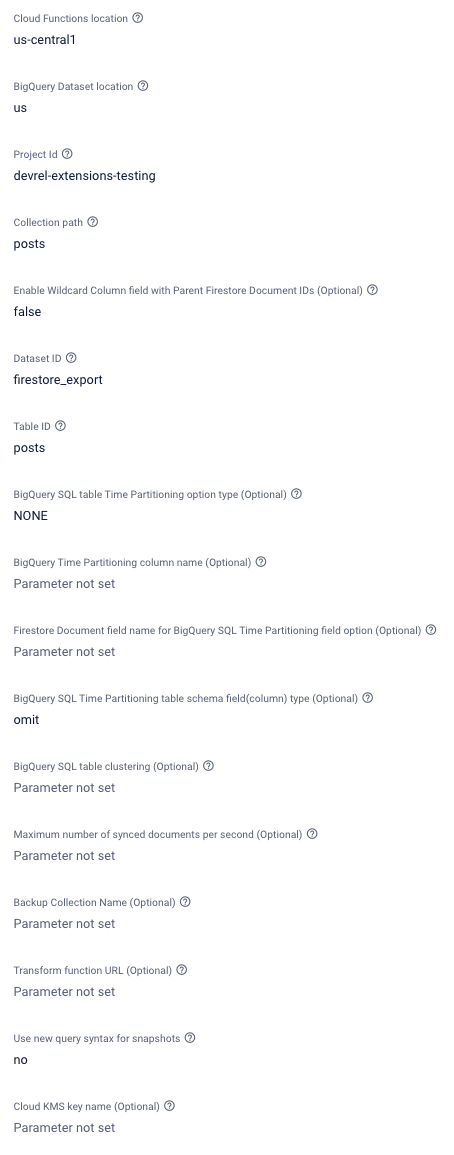
- Cloud Functions location:
- Description: Where do you want to deploy the functions created for this extension? You usually want a location close to your database. For help selecting a location, refer to the location selection guide.
- BigQuery Dataset location:
Where do you want to deploy the BigQuery dataset created for this extension? For help selecting a location, refer to the location selection guide - Project Id:
Override the default project bigquery instance. This can allow updates to be directed to a bigquery instance on another project. - Collection path:
What is the path of the collection that you would like to export? You may use a wildcard notation to match a subcollection of all documents in a collection (for example: chatrooms/{chatid}/posts). Parent Firestore Document IDs from {wildcards} can be returned in path_params as a JSON formatted string.. - Enable Wildcard Column field with Parent Firestore Document IDs (Optional):
If enabled, creates a column containing a JSON object of all wildcard ids from a documents path. - Dataset ID:
What ID would you like to use for your BigQuery dataset? This extension will create the dataset, if it doesn’t already exist. - Table ID:
What identifying prefix would you like to use for your table and view inside your BigQuery dataset? This extension will create the table and view, if they don’t already exist. - BigQuery SQL table Time Partitioning option type (Optional):
This parameter will allow you to partition the BigQuery table and BigQuery view created by the extension based on data ingestion time. You may select the granularity of partitioning based upon one of: HOUR, DAY, MONTH, YEAR. This will generate one partition per day, hour, month or year, respectively. - BigQuery Time Partitioning column name (Optional):
BigQuery table column/schema field name for TimePartitioning. You can choose a schema available as a timestamp OR a new custom defined column that will be assigned to the selected Firestore Document field below. Defaults to pseudo column_PARTITIONTIMEif unspecified. Cannot be changed if Table is already partitioned.. - Firestore Document field name for BigQuery SQL Time Partitioning field option (Optional):
This parameter will allow you to partition the BigQuery table created by the extension based on selected. The Firestore Document field value must be a top-level TIMESTAMP, DATETIME, DATE field BigQuery string format or Firestore timestamp(will be converted to BigQuery TIMESTAMP). Cannot be changed if Table is already partitioned.- Example:
postDate
- Example:
- BigQuery SQL Time Partitioning table schema field(column) type (Optional):
Parameter for BigQuery SQL schema field type for the selected Time Partitioning Firestore Document field option. Cannot be changed if Table is already partitioned. - BigQuery SQL table clustering (Optional):
This parameter will allow you to set up Clustering for the BigQuery Table created by the extension. (for example: data,document_id,timestamp- no white spaces). You can select up to 4 comma separated fields. The order of the specified columns determines the sort order of the data. Available schema extensions table fields for clustering: document_id, timestamp, event_id, operation, data. - Maximum number of synced documents per second (Optional):
This parameter will set the maximum number of synchronized documents per second with BQ. Please note, any other external updates to a Big Query table will be included within this quota. Ensure that you have a set a low enough number to compensate. Defaults to 10. - Backup Collection Name (Optional):
This (optional) parameter will allow you to specify a collection for which failed BigQuery updates will be written to. - Transform function URL (Optional):
Specify a function URL to call that will transform the payload that will be written to BigQuery. See the pre-install documentation for more details. - Use new query syntax for snapshots:
If enabled, snapshots will be generated with the new query syntax, which should be more performant, and avoid potential resource limitations. - Cloud KMS key name (Optional):
Instead of Google managing the key encryption keys that protect your data, you control and manage key encryption keys in Cloud KMS. If this parameter is set, the extension will specify the KMS key name when creating the BQ table. See the PREINSTALL.md for more details. - Events (Optional):
Developers have the option to listen to events emitted by the extension through EventArc. Here you multi-select from the following options: onStart, onSuccess, onError and onCompletion. The emitted events will contain event metadata including data of the synced document.
How it works
The Big Query extension (firestore-bigquery-export) lets you automatically mirror documents in a Cloud Firestore collection to BigQuery. Adding a document to the collection triggers the extension to write a new row to a dataset containing a table and view.
The extension supports the following features:
- Mirroring subcollections (using wildcards)
- Data partitioning
- Clustering
- Custom data transformer functions
This extension also includes tooling to assist with generation of SQL schemas from a Cloud Firestore collection and backfilling data from an existing collection.
During the installation, the extension will automatically create the necessary datasets and tables based on the configuration provided, the following table and view will be included:
- {datasetId}.{tableId}_raw_changelog
The change-log table stores records of every document-write within the collection. This table keeps a record of all write events, such as whether a record was created, updated, or deleted along with the additional information such as a timestamp, path parameters (if enabled), the change type, document ID, and name.
- {datasetId}.{tableId}_raw_latest
The latest view is a reflection of the current data stored within the collection. If a document is created, a new record in the view is added. If a document is updated, the row within the view will be modified to reflect the latest document snapshot data. If a document is removed, the record will be removed from the view.
For every change made to the specified Firestore collection, an update will be added to the relevant views and tables.
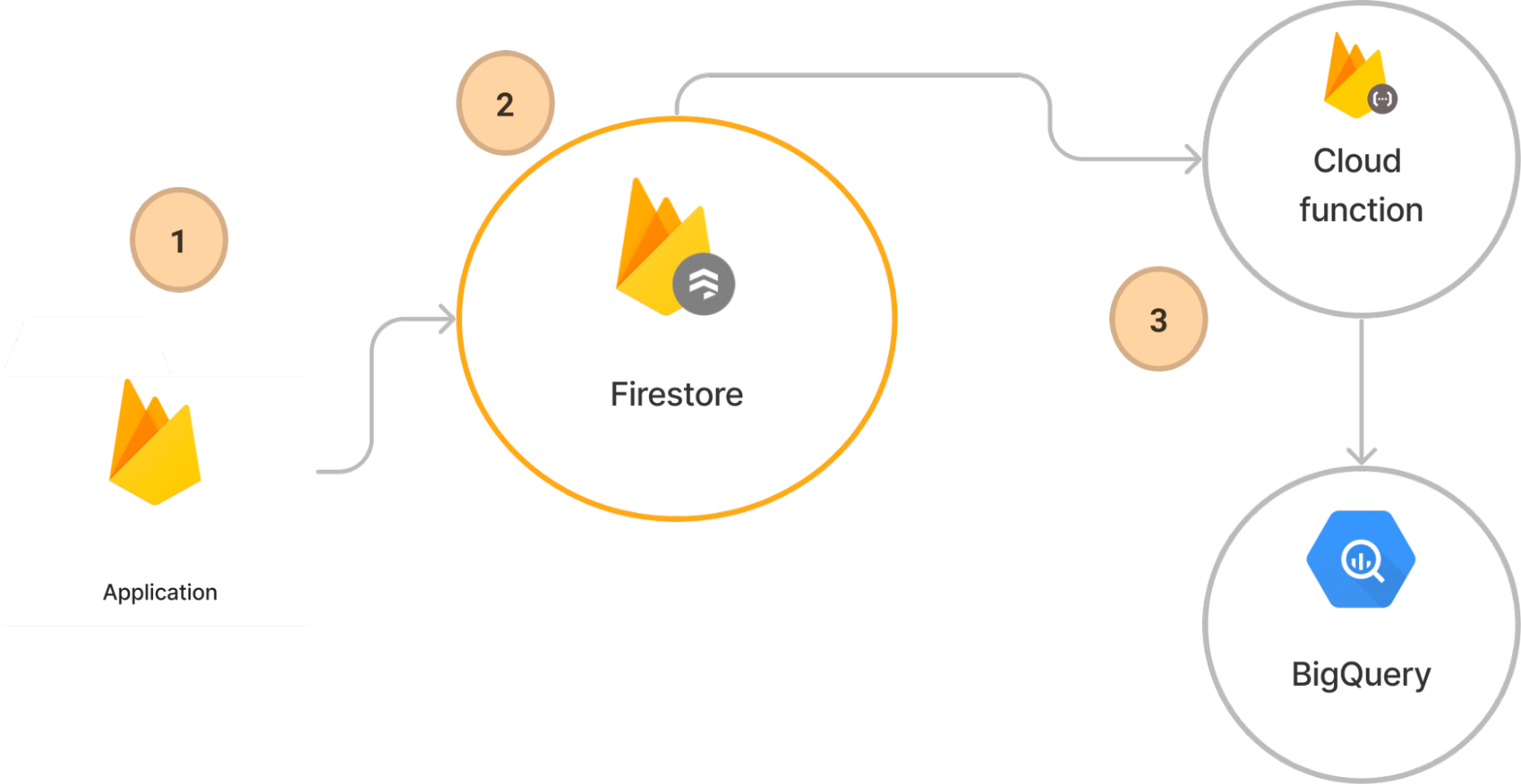
- Make a change to your defined database collection: Making the change through a client or through the console will start the sync process.
- Firestore updates: The saved changes will update the Firestore database, this will trigger any listeners with the updated document data.
- Cloud function Trigger: The extension automatically creates a trigger to listen for changes, the triggered document will be included and sent to BigQuery as an update in a predefined schema. BigQuery will receive the updates from the Cloud function, and in turn save the data in the specified table.
Conclusion
By installing the Stream Firestore to BigQuery extension, you can automatically sync your data with BigQuery, allowing you to analyze your applications Firestore data through BigQuery’s powerful suite of tools.